
Your search pipeline found 50 candidate documents. Now what? The reranker decides which ones the AI actually reads. Get this wrong, and your chatbot answers from the wrong document — confidently. Here's how to choose the right approach.
Why Reranking Matters
The first search stage — keyword matching and vector similarity — is fast but imprecise. It returns roughly relevant documents, but the ordering is often wrong. Your pricing page might rank below a blog post that mentions pricing in passing.
Retrieval is about casting a wide net. Reranking is about keeping only the best results.
The reranker takes the top 20–30 candidates and re-scores them with a more accurate model. The top 5–10 survivors become the AI's context for answering.
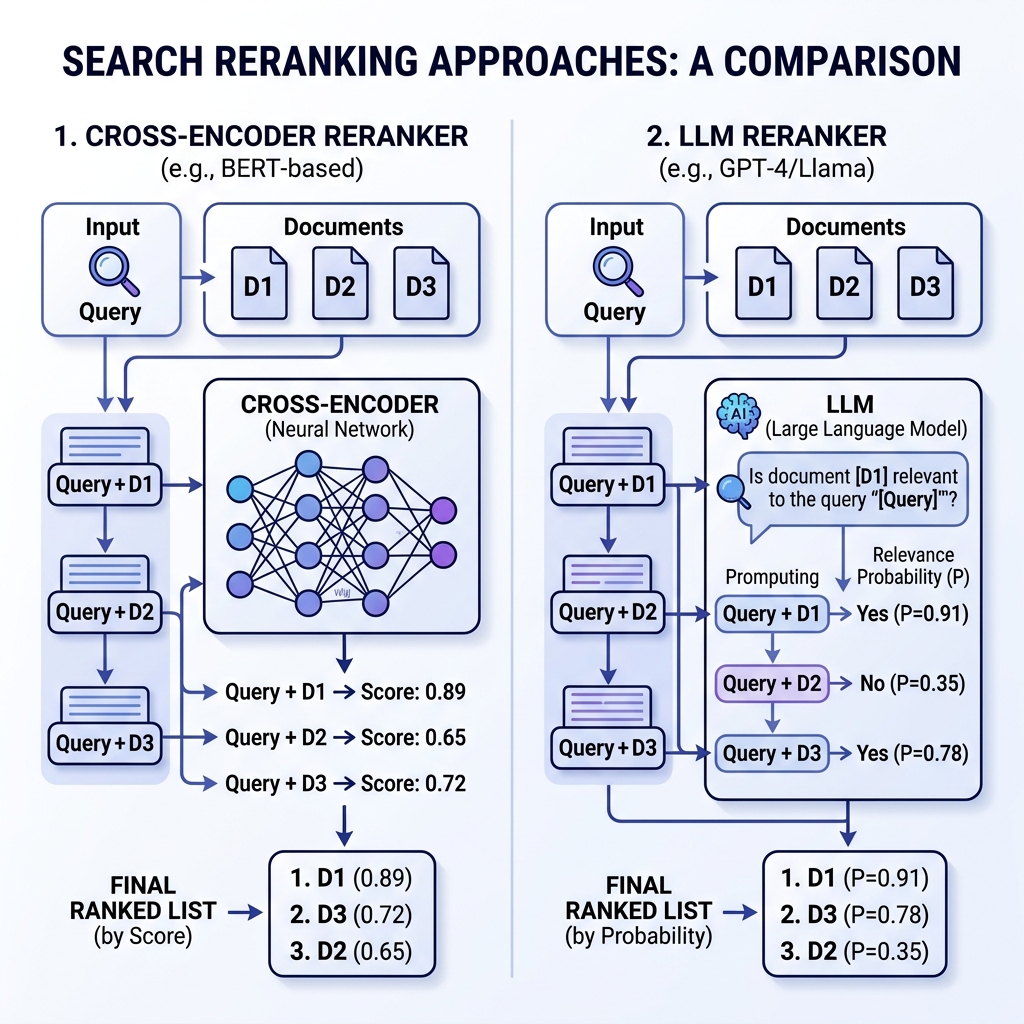
Approach 1: Cross-Encoder
A specialized model trained specifically for relevance scoring. It processes the query and document together — the query tokens attend to the document tokens — catching nuances that separate embeddings miss.
Example: "laptop return policy"
| Document | Score | Why |
|---|---|---|
| Returns & Refunds page (mentions "laptop") | 0.92 | Trained to match "return policy" + product |
| Laptop product page (no return info) | 0.45 | About laptops, not about returns |
| General FAQ (mentions returns briefly) | 0.38 | Related but not specific |
Approach 2: LLM Logprob Reranking
Instead of a specialized model, you ask a general-purpose LLM: "Is this document relevant? Yes or No." But instead of reading the text answer, you read the probability behind it — how confident the model is.
Example: "How do I cancel my subscription?"
| Document | Score | Why |
|---|---|---|
| Subscription Management ("modify, pause, or end your plan") | 0.94 | LLM understands "cancel" = "end your plan" |
| Billing FAQ (mentions "cancel" directly) | 0.88 | Direct keyword match, less comprehensive |
| Pricing page (lists all plans) | 0.22 | Related topic but not about canceling |
The Exact-Match Problem
Both approaches share a failure mode. Query: "error code E-4021"
| Position | Search Score | Reranker Score |
|---|---|---|
| Top 1–3 | 75% | 25% |
| 4–10 | 60% | 40% |
| 11+ | 40% | 60% |
Side-by-Side Comparison
| Dimension | Cross-Encoder | LLM Logprob | Winner |
|---|---|---|---|
| Speed (20 docs) | ~200ms | ~300ms | Cross-Encoder |
| Understanding depth | Pattern matching | Full reasoning | Logprob LLM |
| Vocabulary mismatch | Moderate | Strong | Logprob LLM |
| Simple queries | Great | Overkill | Cross-Encoder |
| Infrastructure | Lightweight (CPU) | Needs LLM/GPU | Cross-Encoder |
| Customization | Needs fine-tuning | Prompt engineering | Logprob LLM |
Which One Should You Use?
Get Started
Related: Query Expansion: The Concept | Implementation Lessons | Knowledge Lint | Auto-Synthesized Knowledge