
Every AI chatbot searches your knowledge base before answering. Most use embeddings. The smart ones also use BM25 — a keyword-matching algorithm from 1994 that, in head-to-head tests, still beats pure neural search for exact questions like "What's the price of Plan B?"
What Is BM25?
BM25 (Best Matching 25) is a ranking function that scores how relevant a document is to a search query based on the words they share. It was developed in the 1990s by Stephen Robertson and Karen Spärck Jones at City University of London.
Despite being 30+ years old, BM25 is still the default ranking algorithm in Elasticsearch, Apache Lucene, PostgreSQL full-text search, and every major search engine. Google used a BM25 variant for years before layering neural approaches on top.
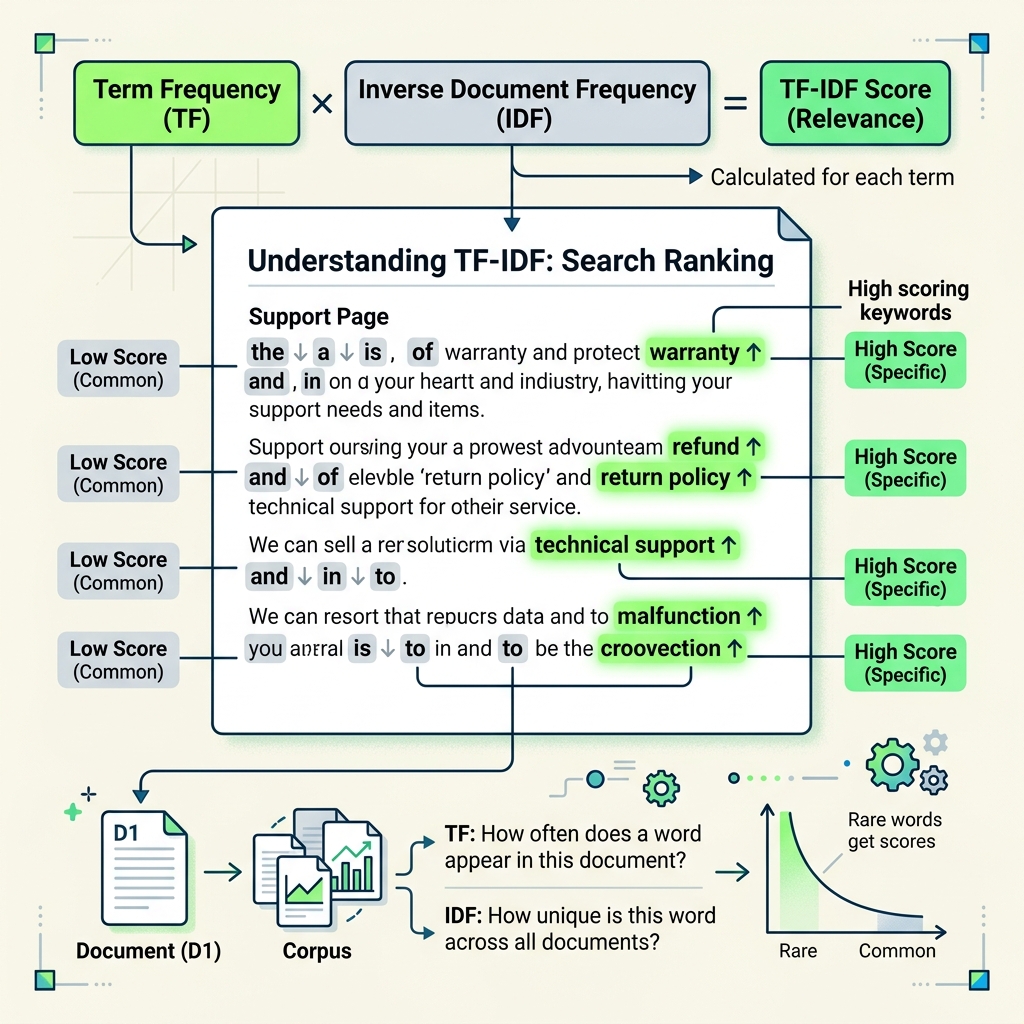
How BM25 Works (Without the Math)
BM25 scores documents based on three intuitions that are surprisingly hard to beat:
BM25 is TF-IDF's smarter cousin. Same idea — rare words in focused documents score highest — but with better math that prevents long documents from dominating.
The BM25 Formula (Simplified)
For those who want the actual formula — here's the simplified version:
| Component | Formula | What It Does |
|---|---|---|
| IDF | log((N - n + 0.5) / (n + 0.5)) | Penalizes common words, rewards rare ones |
| TF saturation | (f × (k1 + 1)) / (f + k1 × (1 - b + b × dl/avgdl)) | Counts word frequency with diminishing returns |
| k1 | Typically 1.2 | Controls how fast TF saturates |
| b | Typically 0.75 | Controls document length normalization |
N = total documents, n = documents containing the term, f = term frequency in this document, dl = document length, avgdl = average document length.
BM25 vs Semantic (Vector) Search
Modern AI chatbots typically use semantic search (embeddings) to find relevant content. Here's how the two approaches compare:
| Dimension | BM25 (Keyword) | Semantic (Embeddings) |
|---|---|---|
| How it works | Matches exact words | Matches meaning via vector similarity |
| "What is your pricing?" | 🟢 Finds pages with "pricing" | 🟢 Finds pages about costs, even without the word |
| "Plan B cancellation policy" | 🟢 Exact match — finds it instantly | 🟡 Might confuse with other plans |
| "I'm unhappy with the service" | 🔴 No keyword match for complaints | 🟢 Understands this is a complaint |
| Speed | 🟢 Sub-millisecond (inverted index) | 🟡 5-50ms (vector similarity) |
| Explainability | 🟢 Clear — "matched on these words" | 🔴 Black box — "closest vector" |
| Zero-shot | 🟢 Works immediately, no model needed | 🔴 Requires embedding model |
| Typo tolerance | 🔴 "pricng" won't match "pricing" | 🟢 Handles misspellings naturally |
Neither approach wins alone. BM25 excels at exact, specific queries. Semantic search excels at vague, intent-based queries. The best systems use both — this is called hybrid search.
Hybrid Search: Why We Use Both
At GetGenius, we run both BM25 and semantic search in parallel, then merge the results using Reciprocal Rank Fusion (RRF). This approach consistently outperforms either method alone:
How We Implement BM25 in Production
We use PostgreSQL with pg_search (formerly ParadeDB) for BM25 scoring. This lets us run BM25 and vector search in the same database — no separate Elasticsearch cluster needed.
When BM25 Wins (And When It Doesn't)
✅ BM25 wins for:
- Specific, keyword-heavy queries — "Plan B pricing", "API rate limits", "return policy"
- Named entities — Product names, feature names, plan names, people's names
- Exact phrases — "30-day money-back guarantee"
- Technical documentation — Error codes, config keys, function names
- Low-latency requirements — BM25 is 10-100× faster than vector search
❌ Semantic search wins for:
- Vague, intent-based queries — "I'm not happy", "something went wrong"
- Paraphrased questions — "How much does it cost?" vs "What's the pricing?"
- Cross-language queries — Query in French, content in English
- Conceptual similarity — Finding content about "refunds" when the query mentions "getting money back"
BM25 Tuning: The k1 and b Parameters
BM25 has two tunable parameters that significantly affect results:
| Parameter | Default | Effect | When to Adjust |
|---|---|---|---|
| k1 | 1.2 | TF saturation speed | Lower (0.5-0.8) for short docs. Higher (1.5-2.0) for long docs where repetition matters. |
| b | 0.75 | Length normalization strength | Set to 0 if all docs are similar length. Set to 1.0 if doc lengths vary wildly (mix of FAQs and long articles). |
The Missing Layer in Most AI Chatbot Platforms
Most AI chatbot platforms primarily rely on vector embeddings for retrieval. They chunk your content, create embeddings, and search by cosine similarity. While some may add basic keyword matching, few implement true hybrid search with BM25 and Reciprocal Rank Fusion.
This works fine for conversational questions but struggles with specific, keyword-heavy ones:
BM25 in the Age of LLMs
Some people assume BM25 is obsolete now that we have LLMs. The opposite is true — BM25 is more important in the RAG (Retrieval-Augmented Generation) era:
- RAG needs retrieval — An LLM can only answer from content you put in its context window. BM25 helps find the right content to include.
- Precision matters — Feeding the LLM wrong documents wastes tokens and produces wrong answers. BM25's exact matching reduces noise.
- Speed matters — In real-time chat, every millisecond counts. BM25 is 10-100× faster than vector search.
- Complementary signals — BM25 and embeddings fail on different queries. Using both covers more ground, as our query expansion approach demonstrates.
BM25 isn't a legacy technology being replaced by AI. It's a foundational retrieval layer that makes AI chatbots more accurate, faster, and more reliable.
Try It Yourself
Want to see hybrid search in action? Our free demo tools let you test how AI answers questions using your own content:
- Chat with Website — Enter any URL and see hybrid search find answers
- Chat with Document — Upload a document and ask specific questions
- Chat with Text — Paste content and test exact-match queries
- AI Visibility Score — Check if your content is optimized for AI search
Related: Query Expansion: Finding More Answers | Cross-Encoder vs Logprob Reranking | Knowledge Lint: Auditing Your Training Data